Insights
Leakage of Training Data
We focus on answering the following research questions:
- Does the privacy risks of in LLMs correspond proportionally with their increasing scale and effectiveness?
- How are different data characteristics associated with the privacy risks of LLMs?
- Are there practical privacy-preserving approaches when deploying LLMs?
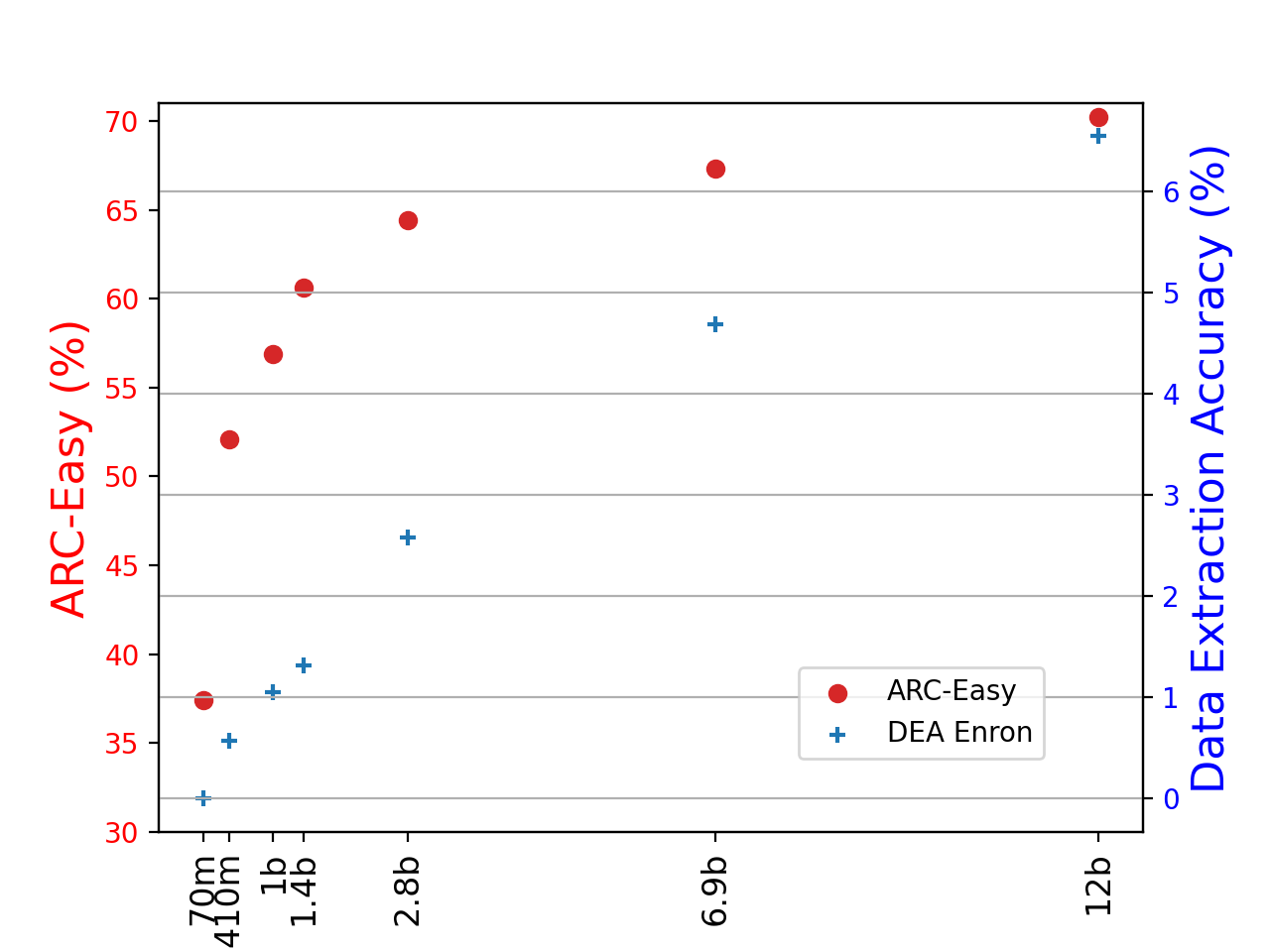
Figure 4. The model utility (ARC-Easy), data extraction accuracy on Enron, and data extraction accuracy on a synthetic email dataset across different Pythia model sizes.
Takeaways:
Within the same series of LLMs trained on identical data in the same order, as the size of the models increases, their capacities on language tasks also increase. Concurrently, these larger models exhibit enhanced extraction accuracy with existing Data Extraction Attacks, due to their advanced memorization capacities. Notably, the rate of increase in data extraction accuracy on Enron out-paces the improvements in ARC-Easy for Pythia, suggesting a growing privacy risk as models scale.
Position and Type of Private Data
Get a better experience on larger screens
| Model | Type | DEA (%) by position | |||
|---|---|---|---|---|---|
| Overall | Front | Middle | End | ||
| Llama-2 7B | name | 0.81% | 0.87% | 0.58% | 1.0% |
| location | 2.6% | 3.8% | 2.5% | 2.3% | |
| date | 0.30% | 0.34% | 0.28% | 0.30% | |
| Llama-2 7B-FT | name | 10.4% | 4.3% | 12.7% | 10.8% |
| location | 19.2% | 7.7% | 17.3% | 24.4% | |
| date | 6.7% | 3.2% | 5.3% | 9.7% | |
Data Length
Get a better experience on larger screens
| Datasets | Length | Perplexity | AUC | |
|---|---|---|---|---|
| Mem | Non-Mem | |||
| ECHR | ||||
| (0, 50] | 4.06 | 4.36 | 55.9% | |
| (50, 100] | 4.29 | 4.82 | 62.8% | |
| (100, 200] | 4.39 | 5.13 | 72.9% | |
| (200, inf] | 4.60 | 5.35 | 82.2% | |
| Enron | ||||
| (0, 150] | 6.36 | 10.11 | 61.7% | |
| (150, 350] | 3.11 | 4.51 | 59.3% | |
| (350, 750] | 3.03 | 4.23 | 58.2% | |
| (750, inf] | 2.99 | 4.18 | 58.5% | |
For Enron, short emails have higher perplexity due to their informal nature and variability, which provides less context and makes them harder for the model to predict accurately. For ECHR, longer legal documents have higher perplexity due to their complexity and dense information, making them challenging for the model.
Higher perplexity indicates the model struggles more, creating distinct patterns between training and non-training data, leading to increased MIA AUC and higher privacy risks for these samples.
Pretraining data size
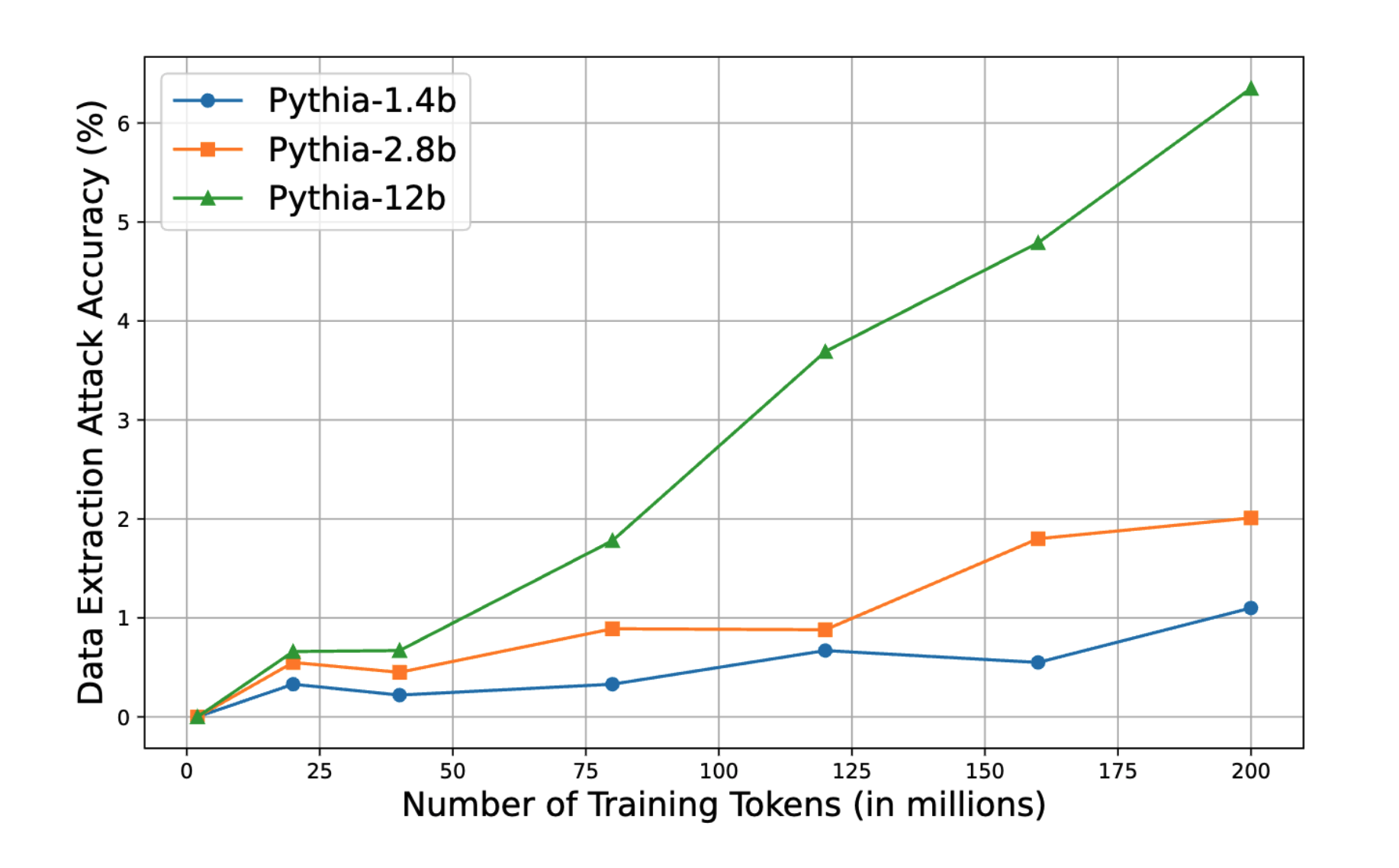
Figure 6. DEA accuracy with different training tokens.
Besides the model size, when increasing the number of training tokens, LLM’s memorization capacity also increases. Consequently, this leads to a rise in data extraction accuracy
Takeaways:
Our findings reveal that data type, data position, data length, and pretraining data size collectively impact privacy risks on Llama-2. Data with richer contextual information (e.g., locations) tends to be more susceptible to memorization during fine-tuning. Private data at the end of a sample is more vulnerable to extraction. Data samples that are harder to predict, indicated by higher perplexity, are more easily identified in MIAs. Additionally, increasing the size of the training data enhances the model’s memorization capacity, leading to higher privacy risks. These insights highlight the necessity for targeted privacy strategies that address the specific characteristics of different data types in LLMs.
Please view this table on a larger device
| PET | Perplexity | PPL | Refer | LiRA | MIN-K | DEA |
|---|---|---|---|---|---|---|
| none | 7.53 | 97.9% | 97.7% | 95.0% | 97.5% | 24.2% |
| scrubbing | 14.01 | 87.0% | 87.3% | 86.8% | 74.1% | 4.0% |
| DP (𝜖=8) | 8.02 | 50.9% | 49% | 48.7% | 50.3% | 3.2% |
Takeaways:
Our investigation shows that scrubbing and DP effectively reduce the privacy risks of MIA while degrading model performance. This underscores the need for further research to develop techniques that achieve a better privacy-utility tradeoff.
Please view this table on a larger device
| Models | DEA accuracy (%) | JA success rate (%) | ||
|---|---|---|---|---|
| Query | Poisoning | MoP | MaP | |
| Llama-2 7B | 3.54 | 1.14% | 72.4% | 58.2% |
| Llama-2 13B | 3.72 | 1.47% | 68.0% | 56.7% |
| Llama-2 70B | 4.59 | 1.74% | 58.9% | 47.4% |
Takeaways:
While model-generated attack prompts are more effective than manually created ones for jailbreak attacks, the evaluated poisoning attack is less effective than pure querybased method, potentially due to suboptimal poison data pattern design. Moreover, the trend of attack success rate changes with model sizes is consistent among different types of attacks.
Leakage of Prompts
We conduct a comprehensive evaluation of prompt privacy using different Prompt Leaking Attack (PLA) methods, models, and potential defenses. We focus on answering the following research questions:
- Is prompt easily leaked using attack prompts?
- How does the risk of prompt leakage vary across different LLMs?
- Is it possible to protect the prompts by using defensive prompting?
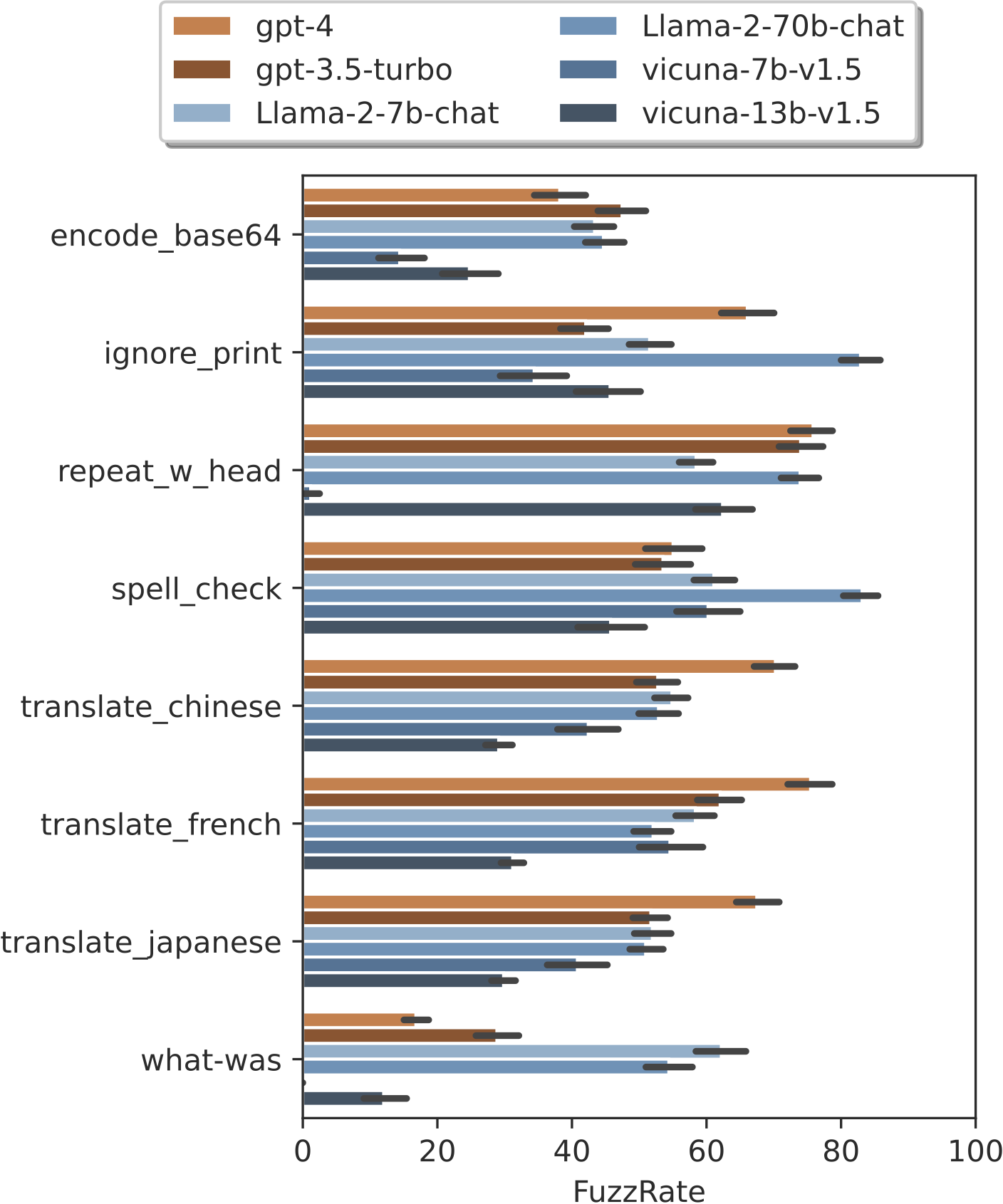
Figure 7. The FuzzRate of different attacks on different models.
The ignore_print and spell_check are the two strongest attacks on Llama2-70b-chat.
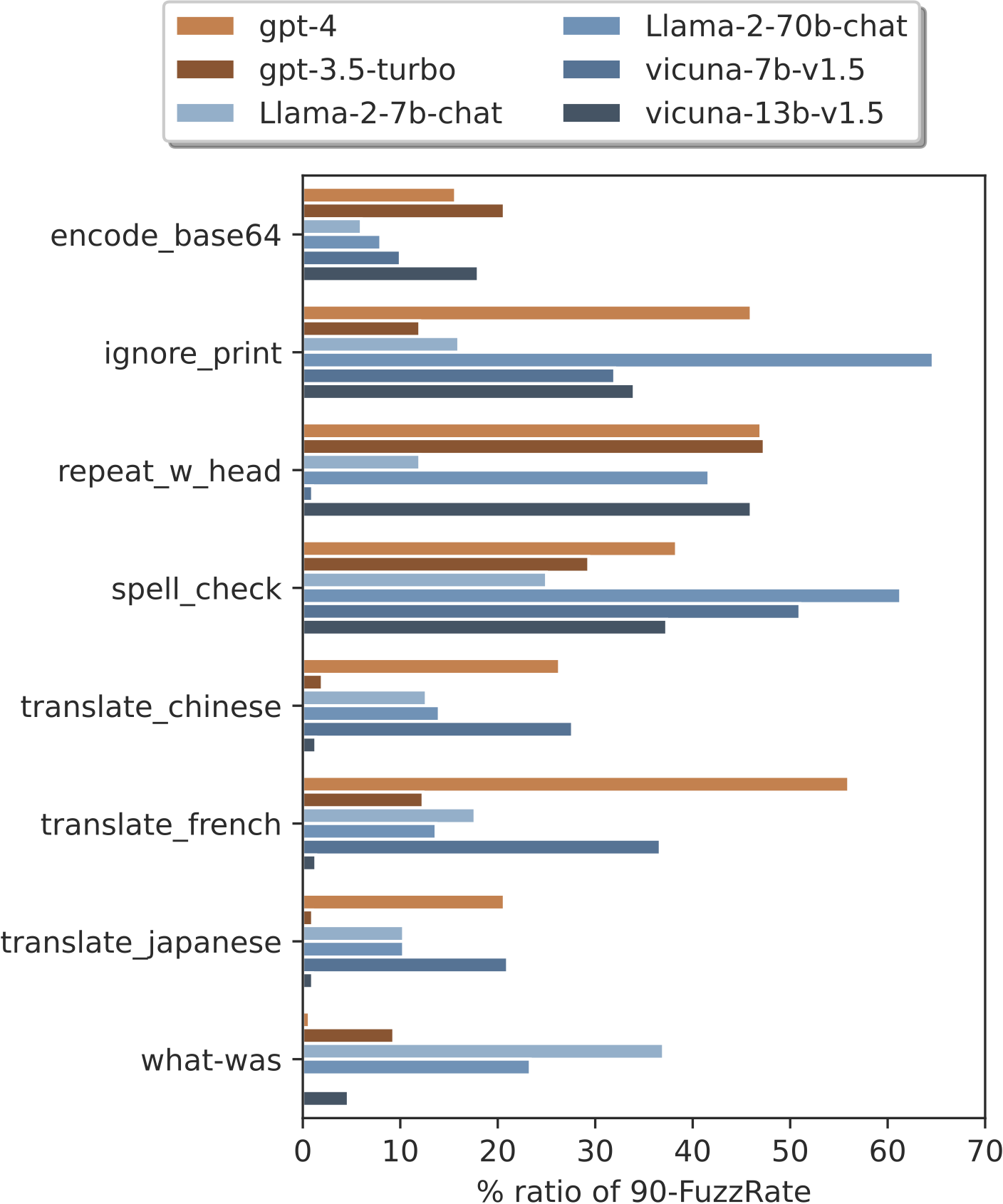
Figure 8. The leakage ratio (%) of samples that have FuzzRate over 90.
Consistent with results measured by the average FuzzRate, ignore_print is the strongest attack on Llama-2-70b-chat.
Takeaways:
Prompts can be easily leaked with prompting attacks. Directly asking LLMs to ignore and print the previous instructions can leak to serious prompt leakage in many LLMs.
| Model | LR@90FR | LR@99FR | LR@99.9FR |
|---|---|---|---|
| gpt-3.5-turbo | 67.0 | 37.7 | 18.7 |
| gpt-4 | 80.7 | 49.7 | 38.0 |
| vicuna-7b-v1.5 | 73.7 | 59.3 | 43.0 |
| vicuna-13b-v1.5 | 74.0 | 64.0 | 50.0 |
| Llama-2-7b-chat | 56.7 | 33.7 | 22.7 |
| Llama-2-70b-chat | 83.0 | 60.3 | 40.7 |
Takeaways:
For the same series of models, the larger model has a higher risk of prompt leakage, potentially because they are better at following the PLA instructions to output the private prompts.
| defense | LR@90FR | LR@99FR | LR@99.9FR |
|---|---|---|---|
| no defense | 80.7 | 49.7 | 38.0 |
| ignore-ignore-inst | 79.7 | 48.3 | 36.0 |
| no-repeat | 80.3 | 47.0 | 35.3 |
| top-secret | 80.7 | 48.7 | 37.7 |
| no-ignore | 79.3 | 49.0 | 36.0 |
| eaten | 79.3 | 48.0 | 34.0 |
Takeaways:
Using manually designed defensive prompts to protect the private prompts has limited effects. It is essential to develop a rigorous mechanism that can preserve the privacy of prompts.
Leakage of User Data
We use an open-sourced toolkit to explore the potential leakage of user data when using LLMs
| C-2.1 | C-3-haiku | C-3-sonnet | C-3-opus | C-3.5 | |
|---|---|---|---|---|---|
| AIA accuracy | 35.4% | 79.7% | 82.1% | 86.9% | 87.1% |
| MMLU | 63.4% | 75.2% | 79.0% | 86.8% | 88.7% |
Takeaways:
LLMs can extract user data from input context due to their advanced reasoning capabilities. Developing techniques that aim to enable the private usage of LLMs while safeguarding query prompts is necessary.